
Тем, кто не осилил Википедию
Мировой объем оцифрованной информации растет по экспоненте. По данным компании IBS, к 2003 году мир накопил 5 эксабайтов данных (1 ЭБ = 1 млрд гигабайтов). К 2008 году этот объем вырос до 0,18 зеттабайта (1 ЗБ = 1024 эксабайта), к 2011 году — до 1,76 зеттабайта, к 2013 году — до 4,4 зеттабайта. В мае 2015 года глобальное количество данных превысило 6,5 зеттабайта. К 2020 году, по прогнозам, человечество сформирует 40-44 зеттабайтов информации.
Сможем ли мы совладать с ней? По расчетам IBS, в 2013 году только 1,5% накопленных массивов данных имело информационную ценность. К счастью, мир спасут технологии обработки больших данных. Они позволят людям объять необъятное и получить из этого пользу. Каким образом — читайте дальше.
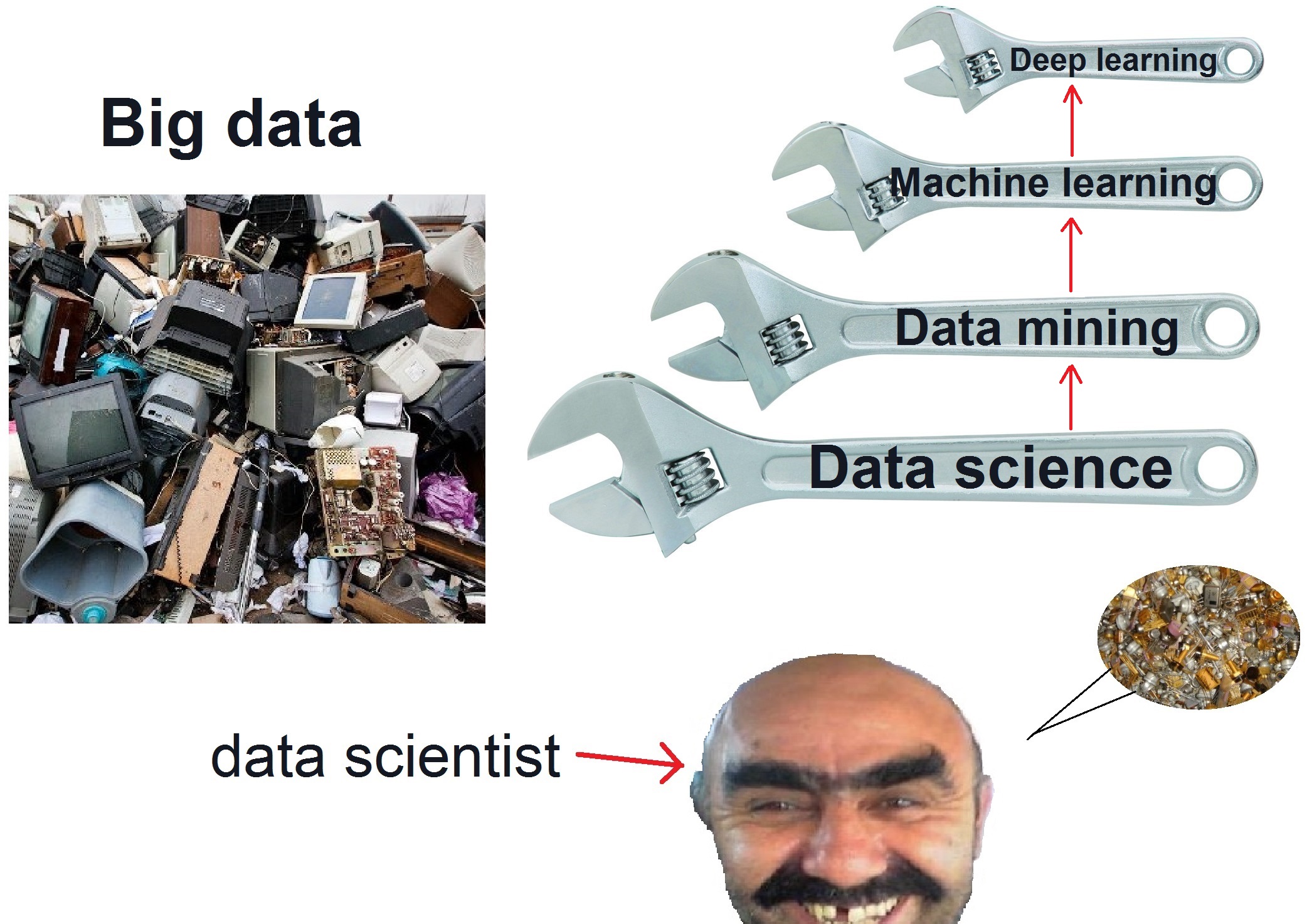
Big data (большие данные) — огромные объемы неоднородной и быстро поступающей цифровой информации, которые невозможно обработать традиционными инструментами.
В русскоязычной среде под большими данными подразумевают также технологии их обработки. В мировой практике большими данными называют только объект анализа.
Данных много, а пользы нет? Только проверенные компании, которые специализируются на Big DataТермин big data родился в 2008 году. Редактор журнала Nature Клиффорд Линч употребил это выражение в спецвыпуске, посвященном взрывному росту мировых объемов информации. Хотя, конечно, сами большие данные существовали и ранее. По словам специалистов, к категории big data относится большинство потоков данных свыше 100 Гб в день.
Анализ больших данных позволяет увидеть скрытые закономерности, незаметные ограниченному человеческому восприятию. Это дает беспрецедентные возможности оптимизации всех сфер нашей жизни: государственного управления, медицины, телекоммуникаций, финансов, транспорта, производства и так далее.
В последние годы big data фактически перестали быть термином. Журналисты и предприниматели сильно злоупотребляли им, и значение размылось. Российские специалисты до сих пор спорят о том, входят ли в понятие big data инструменты работы с ними. Западные эксперты считают этот термин окончательно дискредитированным и предлагают от него отказаться.
Data lake (озеро данных) — хранилище больших данных в необработанном виде.
«Озера» хранят данные из разных источников и разных форматов. Это обходится значительно дешевле традиционных хранилищ, в которые помещаются только структурированные данные. Data lake позволяют анализировать большие данные в исходном виде. К тому же пользоваться «озерами» могут сразу несколько сотрудников.
Data science (наука о данных) — дисциплина, изучающая проблемы анализа, обработки и представления информации в цифровой форме.
Датой возникновения термина считают 1974 год, когда датский информатик Петер Наур издал книгу «A Basic Principle of Data Science».
С начала 2010-х годов наука о данных перестала быть чисто академической дисциплиной. Под влиянием популяризации больших данных data science оказалась перспективным бизнесом. Тогда же профессия data scientist стала одной из самых востребованных и высокооплачиваемых в мире.
В понятие data science входят все методы обработки оцифрованной информации и проектирования баз данных. Некоторые специалисты считают термин data science наиболее адекватной заменой big data в смысле сферы деятельности и рыночной ниши.
Data mining (добыча информации) — интеллектуальный анализ данных с целью выявления закономерностей.
Израильский математик Григорий Пятецкий-Шапиро ввел этот термин в 1989 году.
Датамайнингом называют как технологии, так и процесс обнаружения в сырых данных ранее неизвестных и практически полезных знаний. Методы data mining находятся на стыке баз данных, статистики и искусственного интеллекта.
Machine learning (машинное обучение) — теория и практика разработки самообучающихся программ, большая область искусственного интеллекта.
Искусственный интеллект и нейронные сети
Machine learning — большая область искусственного интеллекта. Программисты учат свои алгоритмы выявлять общие закономерности по частным случаям. В результате компьютер принимает решения исходя из собственного опыта, а не команд человека. Многие методы такого обучения относятся к датамайнингу.
Первое определение машинному обучению дал в 1959 году американский информатик Артур Самуэль. Он написал игру в шашки с элементами искусственного интеллекта — одну из первых самообучающихся программ в мире.
Deep learning (глубокое обучение) — вид машинного обучения, создающий более сложные и более самостоятельные обучающиеся программы.
При обычном машинном обучении компьютер извлекает знания через управляемый опыт: программист дает алгоритму примеры и вручную исправляет ошибки. А при deep learning система сама проектирует свои функции, делает многоуровневые вычисления и выводы об окружающем мире.
Глубокое обучение применяют к нейронным сетям. Сферы применения этой технологии — обработка изображений, распознавание речи, нейромашинный перевод, вычислительная фармацевтика и другие прорывные технологии, внедряемые IT-гигантами вроде Google, Facebook и Baidu. Глубокое обучение стало одной из самых востребованных областей информационных технологий.
Доподлинно неизвестно, кто впервые применил термин к нейронным сетям. Deep learning стало популярным в 2007 году, когда канадский ученый Джеффри Хинтон создал алгоритмы глубокого обучения многослойных нейронных сетей.
В общем, выходит как-то так:
Искусственная нейронная сеть — система соединенных простых процессоров (искусственных нейронов), имитирующая нервную систему человека.
Благодаря такой структуре нейронные сети не программируются, а обучаются. Как и настоящие нейроны, процессоры просто принимают сигналы и передают их своим собратьям. Но вся сеть способна выполнять сложные задачи, с которыми не справляются традиционные алгоритмы.
Использование нейросетей
Понятие искусственных нейронных сетей ввели американские ученые Уоррен Маккалок и Уолтер Питтс в 1943 году. Сегодня нейросети используют для распознавания образов, классификации, прогнозирования, нейросетевого сжатия данных и других практических задач.
Business intelligence (бизнес-аналитика) — поиск оптимальных бизнес-решений с помощью обработки большого объема неструктурированных данных.
Эффективный business intelligence анализирует внешние и внутренние данные — как рыночную информацию, так и отчетность компании-клиента. Это дает полную картину бизнеса и позволяет принимать как операционные, так и стратегические решения (выбрать как цену продукта, так и приоритеты развития компании).
Термин появился в 1958 году в статье исследователя из IBM Ханса Питера Луна. В 1996 году аналитическое агентство Gartner, которое специализируется на изучении IT-рынка, включило в состав business intelligence методику датамайнинга.
Если у вас другое восприятие этих терминов, ругайтесь в комментариях :)
Материалы по теме:
Яндекс разработал нейросети, которые помогут врачам ставить диагнозы
Ученые смогут прочитать мысли птицы с помощью алгоритма нейронной сети
Американская разведка назвала российскую нейронную сеть по распознаванию лиц лучшей в мире
Пользователь Reddit выпустил нейросеть для замены лиц актеров в порно
Как устроены искусственные нейронные сети: видео
Фото на обложке предоставлено сайтом Shutterstock.
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 Всё об Open Banking: что вас ждёт, если вы не будете в тренде?
- 2 Что такое Big data: собрали всё самое важное о больших данных
- 3 Как FinTech использует большие данные — хрестоматийные примеры
- 4 26 терминов в финтехе, которые нужно знать
- 5 MarTech-словарь: термины, которые стоит знать каждому маркетологу
ВОЗМОЖНОСТИ
29 апреля 2024
30 апреля 2024